Skip to content
Menu
Home
Aplikasi
Games
Review
Tutorial
Berita
Minglebox.Com
Menu
Home
Aplikasi
Games
Review
Tutorial
Berita
Photomath Mod Apk (Unlocked Plus/Premium)
by
admin
8 Laptop 3 Jutaan Terbaik (Sudah Support SSD dan RAM Besar) !
by
Dika
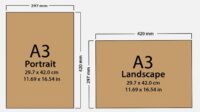
Daftar Ukuran Kertas A3 dalam Satuan Mm, Inci, Cm, dan PX
by
Amira
5 WhatsApp Mod Terbaik Lengkap dengan Link Downloadnya 2023
by
Amira
3 Cara Setting Whatsapp Agar Tidak Terlihat Online
by
Desy
8 Cara Memperkuat Sinyal WiFi
by
Dika
Older posts
Page
1
Page
2
…
Page
10
Next
→